While I'm fortunate enough to develop software for state-of-the-art companies, I've always been the "printer guy", a badge I wear with pride.
And maybe that's the reason why, for more than a quarter of a century, people have turned up with storage medium to salvage. I never did it professionally, it’s just something I enjoy and, more often than not, I’m able to help.
The process
My main approach is two-fold:
- capture what you can from the dying medium
- try to recreate the data
Sometimes, just by adjusting read tolerance, you're able to capture everything from a disk Windows or Mac reject, as the OS times out faster than the dying medium can respond. I've had a disk hooked to a box for 7 months; 100% recovery success!
Sometimes you'll have chunks of data missing, but one of the File Allocation Table / Master File Table / Container superblock / root B-tree are still there and so most data is salvageable with both filenames and tree location.
At the extreme, you’re left with nothing but some of the raw data. All you can do is carve it out - essentially reading every byte from the medium, identifying known headers like JPG (FF D8) or MKV (1A 45 DF A3), and proceed to capture all sequential data until the end of the file. If for any reason, the file is fragmented, carving will obviously fail.
The call from Pierre Zago
Frankie, this hasn't happened before, I'm generally cautious... I don't know what I was thinking - I've accidentally formatted an SD card with audio for an entire session. Worse, I've saved some files onto it!
Pierre is an incredibly talented comedian and an extraordinary actor. While his work is multifaceted, he became widely known for street sketches, some of them absolutely universal. Just check the one below where he simply says "excuse-me".
This sketch’s simplicity and comedic charm create a lighthearted yet universally appealing work of art.
With that simple action, Pierre had joined the club. Everyone messes up. Even Pixar. Don't worry, I said, while taking the card, the overwritten contents are gone, but given that it's a microphone formatted card, even without FAT tables we should be able to carve out most of whatever you've recorded as data will probably be sequential.
Little did I know, this would turn out to be one of the most interesting toy projects I’ve worked on in a while. The last time I had this much fun was rebuilding a hardware RAID-0 that contained the masters for an album by 'Os Azeitonas'.
The Echo (echo, echo)...
As expected, the only way to get data back was by carving it out of the image dump. There's a multitude of tools to choose from, Photorec (open source), Recuva (watch out for bundleware), ReclaiMe (paid), etc... though I'm partial to R-Studio (paid); their results consistently outperform the competition.
In this instance, nonetheless, things wouldn't be so simple. Every software tried was able to extract the wav files, but there was something rather wrong with the data as they all had this repetition, an echo of sorts.
I'm a bit dull of hearing, so opened them in Audacity to check what was going on. You can clearly see a pattern here:
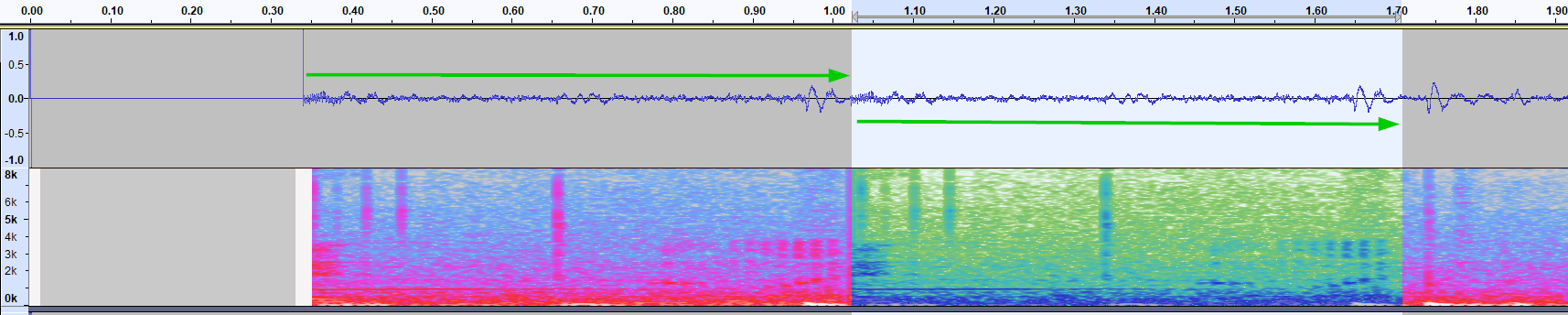
While the chunks have a pretty similar waveform - there isn't any sort of binary correlation. Besides, there was also something murky, every wav file had what appeared to be 2 consecutive headers.
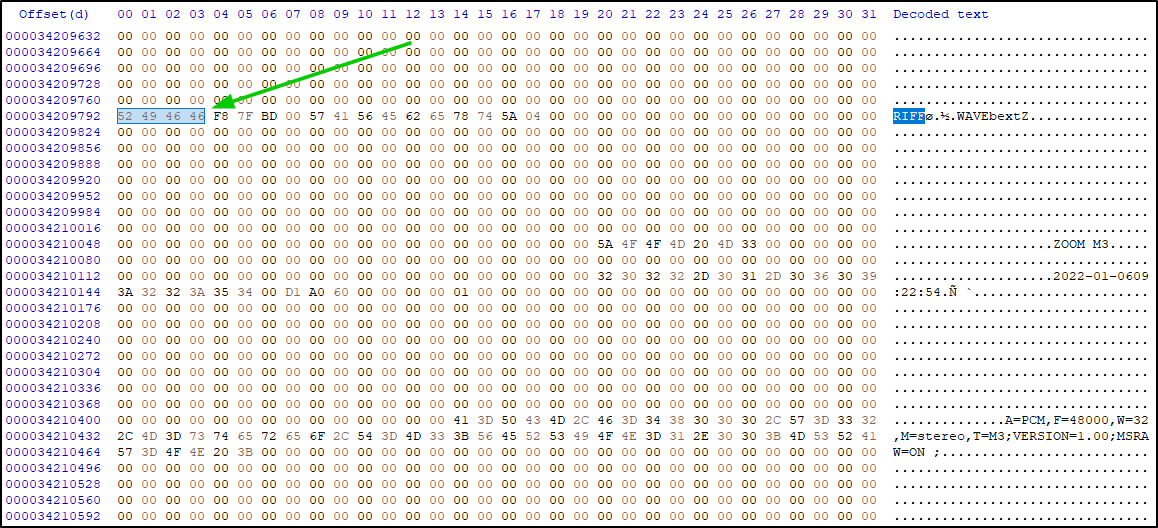
Mind you, at this point, my knowledge of wav files was that the header is 52 49 46 46. Aside from using a mic, I didn't query Pierre on how he had actually recorded the data. However, when I saw "ZOOM M3" tag in the header, I called the authority on everything sound.
Perfect Pitch, a sort of wizardry
Ed's been on speed dial for the better part of this lifetime. I'm lucky like that. Beyond being an unbelievable composer - just listen to the breathtaking Best Youth - he's also a pitch-perfect, living and breathing, encyclopedia on sound.
Zoom? Yes, yes. I have one. They record both wav and raw. Data is mangled? Ah. Sure. Recover? Twisted files? That's going to be an impossible task and, even if it's not, it'll be easier to just re-record.
And there he had me. It would definitely be easier to just re-record, even Pierre at one point suggested doing a voice-over, but where would the fun be in that?

The Magic Number
I didn't even appreciate the concept of a raw wave until Ed explained it, but now I knew the mic saves two simultaneous files, everything fell into place.
It's common for digital cameras to store both formats, but a microphone is a different beast. There's no way to determine upfront how long the user will record, which wouldn't be an issue if this were a single stream. As it's storing both tracks, there is quite a bit more play involved.
You see, as soon as you hit record, the mic creates two files and continuously flushes the captured data from both onto the card. That, is done in chunks of data. One for the RAW, another for the WAV, repeat.
Since we need to isolate those slices of data in order to untangle it, we must know their exact size. And there lies our magic number!
My first thought was that the chunks might be aligned with exFAT allocation unit size. In this case, 128 KBytes. Let's test it.
The header, clearly states that this is a stereo file (2 channels), recorded at 32 bits per channel, sampled 48k times per second. If you remember from the image above, the chunks repeat at approximately 0.7 seconds.
Let's get a rough approximation on the chunk bytes so we know the ballpark.
1 second of data = 2 channels * 32 bits * 48000 samples
1 second of data = 384000 bytes
0.7 seconds ~ 268800 bytesWe're looking into chunks of around 268 KBytes.
And just like that, the idea that data may be chunked to exFAT AUS of 128 Kbytes is instantly disproved.
The next obvious step would be to travel upwards on base 2. Given that 4096 is a good balance for buffers, let's evaluate from there:
4096 * 32 = 131072 (falls short by about 1/2)
4096 * 64 = 262144 (is in the ballpark of what we're expecting)
262144/384000 ~ 0.682 seconds of data
0.682 seconds matched our estimate of 0.7 seconds so perfectly that I immediately knew 262144 was the constant we were after.
The reconstruction
Conceptually, the problem was solved. Now it was just a matter of building the tool. For that it would be necessary to:
- Untangle the files directly from the image dump. Since pieces recovered by other carving software would be half the expected size (the data chunk contains two files, so it’s actually double the size reported).
- Learn how to create a RIFF header.
- Create a RIFF header with a BEXT chunk to make the recovered files compatible with the "M3 ZOOM Edit & Play" software.
And I'm pretty sure you'll feel more at home there.
However, for the sake of Google indexing, I’m leaving the methods that create both the RIFF and BEXT headers here, something I couldn’t find, which unfortunately made the process take longer than I’d like to admit.
public class RiffFile {
/**
* Creates a RIFF header with BEXT and fmt chunks
*
* @param sampleRate the sample rate of the audio (8000Hz, 44100Hz, 48000Hz, etc) times per second the audio is sampled
* @param bitsPerSample the bits per sample (8bits, 16bits, 32bits, etc)
* @param channels the number of channels (1 mono, 2 stereo, etc)
* @param audioDataSize the size of the audio data in bytes
* @return the RIFF header
* @throws IOException if an I/O error occurs
*/
public static byte[] createRiffHeader(int sampleRate, short bitsPerSample, short channels, int audioDataSize) throws IOException {
// calculate the byte rate, block align and file size
int byteRate = sampleRate * channels * bitsPerSample / 8;
short blockAlign = (short) (bitsPerSample * channels / 8);
// stream that will carry the new RIFF file
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
DataOutputStream out = new DataOutputStream(byteArrayOutputStream);
// riff header
out.writeBytes("RIFF");
out.writeInt(Integer.reverseBytes(0));
out.writeBytes("WAVE"); // 9-12 Format always WAVE
// bext chunk
writeBextChunk(out);
// fmt chunk
out.writeBytes("fmt "); // 13-16 chunkID is "fmt " with trailing whitespace
out.writeInt(Integer.reverseBytes(16)); // 17-20 size of this chunk, is 16 byts
out.writeShort(Short.reverseBytes((short) 3)); // 21-22 (2 bytes) audioFormat (1 PCM integer, 3 IEEE 754 float)
out.writeShort(Short.reverseBytes(channels)); // 23-24 (2 bytes) numChannels (1 mono, 2 stereo, 4, etc)
out.writeInt(Integer.reverseBytes(sampleRate)); // 25-28 (4 bytes) sampleRate (8000, 44100, 48000, etc)
out.writeInt(Integer.reverseBytes(byteRate)); // 29-32 (4 bytes) byteRate (sampleRate * numChannels * bitsPerSample/8)
out.writeShort(Short.reverseBytes(blockAlign)); // 33-34 (2 bytes) blockAlign (numChannels * bitsPerSample/8)
out.writeShort(Short.reverseBytes(bitsPerSample)); // 35-36 (2 bytes) bitsPerSample (8bits, 16bits, 32bits, etc)
// data chunk
out.writeBytes("data"); // 37-40 chunkID ID is "data"
out.writeInt(Integer.reverseBytes(audioDataSize)); // 41-44 size of this chunk varies
out.close();
// write the full size of the file on the 4-8 bytes
byte[] outArr = byteArrayOutputStream.toByteArray();
int size = outArr.length - 8;
ByteBuffer.wrap(outArr, 4, 4).order(ByteOrder.LITTLE_ENDIAN).putInt(size);
return outArr;
}
private static void writeBextChunk(DataOutputStream out) throws IOException {
// bext chunk
out.writeBytes("bext");
out.writeInt(Integer.reverseBytes(256 + 32 + 32 + 10 + 8 + 8 + 8 + 2 + 180 + 4 + 4 + 4 + 4 + 4 + 180)); // bext chunk size (fixed size for BWF)
// description 256 bytes
writeToArray(out, 256, ""); // 256 bytes description
writeToArray(out, 32, "ZOOM M3"); // 32 bytes originator
writeToArray(out, 32, ""); // 32 bytes originator reference
writeToArray(out, 10, "2023-10-01"); // 10 bytes origination date
writeToArray(out, 8, "12:00:00"); // 8 bytes origination time
writeToArray(out, 8, "12:00:00"); // 8 bytes time reference
out.writeLong(Long.reverseBytes(0L)); // 8 bytes time reference
out.writeShort(Short.reverseBytes((short) 0)); // 2 bytes version
out.write(new byte[180]); // 180 bytes UMID
out.writeFloat(0.0f); // 4 bytes loudness value
out.writeFloat(0.0f); // 4 bytes loudness range
out.writeFloat(0.0f); // 4 bytes max true peak level
out.writeFloat(0.0f); // 4 bytes max momentary loudness
out.writeFloat(0.0f); // 4 bytes max short term loudness
// zoom m3 needs this bit to allow file to be read from "zoom m3 edit & play"
writeToArray(out, 180, "A=PCM,F=48000,W=32,M=stereo,T=M3;VERSION=1.00;MSRAW=ON ;");
}
}As you may see, there wasn't much effort put into the BEXT chunk; I simply created it to ensure "Zoom M3 Edit & Play" would be compatible.
The Tool
I hope you had an interesting read. I tried to lift the curtain on the thought process while keeping this engaging. The actual code is hopefully self-explanatory, and you will find it here:
 wasteofserver
wasteofserverThe challenge wasn't just about recovering lost recordings - it was about understanding why traditional tools failed and developing a method that worked.
While it might have been easier to re-record, the thrill of solving the puzzle made the effort worthwhile. In the end we got a custom-built solution that successfully restores Zoom M3 MicTrak recordings.
If you ever find yourself in a similar situation, hopefully, this breakdown helps you out. And if not, well, at least you got to enjoy a little adventure into the world of data recovery.
As an Amazon Associate I may earn from qualifying purchases on some links.
If you found this page helpful, please share.