GlitchTip - track code, monitor servers Here at Waste of Server, we recently started using GlitchTip, and we're sold. This is a short read on how to quickly set it up while allowing internal SSL certs.
TP-Link HS100 - Godsend for Smart Home Integration The following code works on the HS100, HS105 and HS110, it may be compatible with more models, but was tested with success on these.
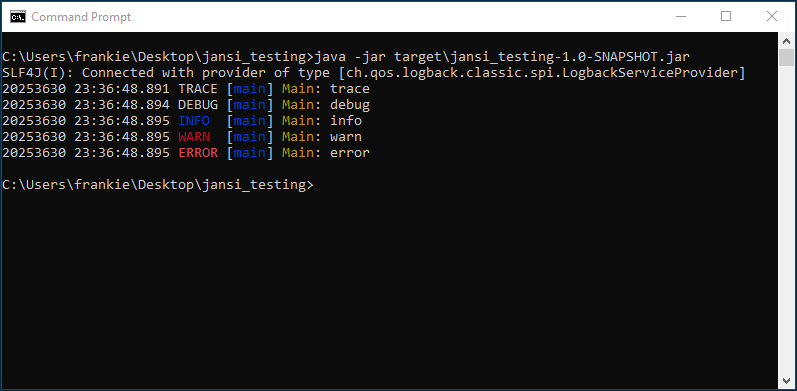
java Java; terminal with ANSI colors in Windows, Linux & IntelliJ I've run into this problem more times than I’d like, always having to retrace my steps to get things working again; so I’m putting this online as a reference.
data-recovery Zoom M3 MicTrak file recovery How a series of inconspicuous events lead to a journey deep into the binary encoding of RIFF files and this data recovery tool
privacy Permanently delete unwanted emails from Gmail. Out of sight, out of mind! Getting unwanted emails from a specific sender and can’t resist checking the trash? This guide will help you remove them for good.
haproxy Stop 404 prying bots with HAProxy If you manage a public facing web server, you'll have noticed that bots try their luck on a myriad of non-existing pages. Leverage HAProxy to stop them at the door.
email Postfix using Gmail as a relay server It's trivial to configure your box to dispatch emails via an external SMTP provider like Gmail.
haproxy Mitigate attacks on WordPress running under Cloudflare - HAProxy and stick-tables How to restrict a user when the IP you're getting hit with belongs to the CDN (Content Distribution Network)? This is a guide on how to leverage an OSI Level 7 Proxy, such as HAProxy, to scope and filter malicious requests.
java Premature optimization, where software thrives unless you kill it first - a tale of Java GC Will a LinkedList be faster? Should I swap the `for each` with an `iterator`? Should this `ArrayList` be an `Array`? This article came to be in response to an optimization so malevolent it has permanently etched itself into my memory.
programming How to calculate P&L While displaying current profits or losses is a number taken for granted in every financial dashboard, it makes for a fun question as it's one of those calculations that can and should be optimized.
programming Interactive Brokers TWS API - and yet it works! If you glance over the forums, it looks like this software was forged in the fires of hell. Follow me in a journey to the depths.
utilities SSH, Mosh and tmux If you're using secure shell to remote, Mosh and tmux should be part of your arsenal.
trivial Pepsi broke the contract An API is a contract with the world, and that makes it one of the hardest things to get right in software design.
java Run bash commands from Java You may want to use `ffmpeg` to convert a bunch of videos, or call `ImageMagick` to manipulate some images. Whatever you may need, calling external programs from Java is pretty straightforward.
reviews Sony WF-1000XM4 vs Apple AirPods Pro Sony, a behemoth of the musical industry versus Apple that, since the iPod debut, stuck a chord with the EarPods and subsequent upgrades.
java Java: How to get all implementations of an Interface You've implemented them all. That was the hard part. Listing them should be easy!
utilities AutoHotKey, the magic keyboard As a developer, I'm constantly pushing for automatization. First target? The keyboard.
Don't forget to backup the cloud! By now, it's a given that you're making backups to the cloud. Are you also backing the cloud up?
java DTO, DAO and Repository Patterns The acronyms and some slight overlap tend to raise questions when programmers first start to implement these techniques.
trivial Linux, find and gzip a bunch of files I've been recently asked if you can traverse a bunch of folders and gzip all files that end in *.csv. Sure you can!